Tools and Techniques for Digital Libraries
by Jacques Ducloy
Two new and important institutes have been recently created in the region of Lorraine: INRIA-Lorraine, which has strengthened a traditional research area in Computer Science, and INIST, a national documentary centre, which has created a new activity in Technical and Scientific Information. In order to initiate a common R&D activity between these two Institutes, it is necessary to solve two complementary issues: to help information specialists to handle the new technologies; to encourage computer scientists to work on distributed documentation systems, ie on Digital Libraries.
With this common objective in mind, INRIA Lorraine, in partnership with the Computer Science Research Center in Nancy, is now working in three main directions: the first activity is dedicated to the development of basic tools for scientific or technical information management and document engineering; a second activity is based on the results of the first and focuses on Information Retrieval Systems; a third important activity is concentrated on the study of linguistic and terminological tools.
A main result of the first topic is the DILIB (Document and Information LIBrary) project: a workbench which uses SGML for coding information or designing tool interfaces. A guiding principle is that all kinds of information, whether external or internal, is coded according to the SGML standards.
DILIB's kernel is a toolkit whose basic part consists in a SGML tree handling library and a set of Unix-like commands for handling SGML records. This permits the design of generic tools which can be applied to any kind of information. For instance, using an SGML path mecha-nism, a selection of all Unimarc records having Dunod as publisher could be written like this:
SgmlSelect -g unimarc/f210/sc#=Dunod
The same filter (SgmlSelect) can be applied on an inverted file to select authors whose frequency is less (or greater) than a given threshold. This 'SGML philosophy' will be applied to many areas relating to Digital Libraries, for instance in designing Information Retrieval Systems. DILIB contains several basic components (such as modules to manage large sets of records) which can be combined to build complex WWW applications linking hetero-geneous sets of data. An interesting feature is the automatic generation of a 'hierarchical type of thesaurus' using clustering mechanisms. Other techniques using neuronal approaches have been tested (in the framework of the INIST NEURODOC project for instance).
In order to handle real Digital Libraries, ie data bases which contain full text records or articles, we are now working using DIENST repositories. DIENST, a distributed Digital Library protocol, is being developed by Cornell University in the framework of NCSTRL (Networked Computer Science Technical Reports Library). Last year, at an ERCIM meeting in Budapest, we presented a first sample of coupling a DILIB browsing graph with a DIENST repository.
Another result of the SGML approach is a strong interoperability which allows a library belonging to a small organization to be integrated in several different networks. For example, the library of our laboratory is a member of the ERCIM network of Digital Libraries (using DIENST and RFC 1807) and GRISELI, a French project for collecting technical reports dealing with the ISO 12083 cataloguing format.
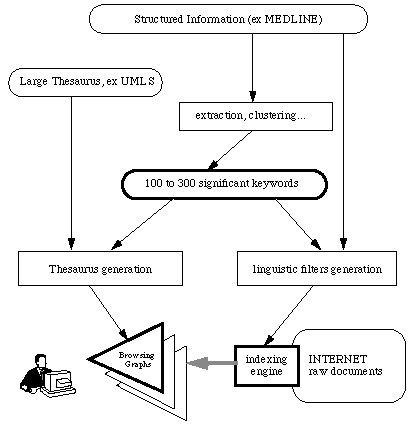
However, the biggest challenge for a Digital Library on the international scene is to master multilinguality and to be able to allow a given community of end users to search large volumes of data using a common terminology base. We are now working on this topic within the framework of the MedExplore project (which is funded by CNRS GIS Sciences de la Cognition). Its aim is to allow a medical expert to search through various kinds of data including structured data (for instance the MEDLINE database and the UMLS thesaurus) and raw textual information coming from INTERNET.
A simplified example of the strategy we intend to apply is the following. If we want to generate a hypertext from a set of raw documents, the first step and a key point of our approach is to build up a significant set of some hundred keywords. This collection of terminological items can be produced in several ways, for instance using a clustering mechanism. We could then apply complementary tools and techniques to produce a browsing graph (for instance by extracting significant relationships from a large thesaurus), and an indexing engine. For each operation, the limited number of keywords allows a choice between purely automatic or human assisted processing. This kind of technique, coming from bibliometric or scientific surveys, can be used in many areas dealing with indexing or multilinguality in the Digital Libraries sector; especially if we want to enforced a federative way of working.
Simplified strategy for hypertext generation.In the framework of ERCIM, we are submitting two proposals: the first one aims at setting up a European Digital Library on Computer Sciences and Applied Mathematics; the second intends to create a Euro-Mediterranean network for information on public health. Both these projects must handle multilinguality a key point for European Digital Libraries.
Please contact:
Jacques Ducloy - INRIA Lorraine & CRIN CNRS
Tel: +33 83 59 30 38
E-mail: Jacques.Ducloy@inria.fr