

ERCIM News No.35 - October 1998
ERCIM News No.35 - October 1998
Intelligent Mediation of Cultural Information Sources
by Bernd Amann, Vassilis Christophides, Irini Fundulaki, Michel Scholl and Anne-Marie Vercoustre
With the emergence of the World Wide Web and other application integration infrastructures such as OMG’s CORBA and Microsoft’s OLE, a large number of autonomous cultural information sources has become accessible to diverse user groups around the world. In this global information space, access to disparate information such as fine-art objects, documents, pictures, etc, is a difficult and complex process. This is due, in particular, to the existence of two types of heterogeneity: the first is of semantic nature, dealing with the different terminologies and conceptualizations employed by the various information providers and consumers while the second one is more of a syntactic nature, due to the variety of the incorporated data structures, for the representation, storage and retrieval of information in the various sources.
INRIA and FORTH have launched a research collaboration (ARTEMIS Project) which is motivated by the need to access and integrate complex and evolving information in a dynamic environment. We rely on the ARPA I3 reference architecture comprising three layers, namely, a Graphical User Interface, a Mediator and several Wrapped Data Sources. Our approach considers high-level languages for information transfer in order to specify and implement I3 tools such as mediators and wrappers. We advocate in this respect a suitable integration of Knowledge Representation and Reasoning technology with Database technology. The former is adopted for the efficient semantic description of sources using ontologies and thesauri and the latter for the integration and caching of query results.
Cultural artifacts such as paintings, statues, buildings can be classified differently according to various techniques, forms, styles, materials and are related to different persons, historical events, places, etc. To capture the different semantics of cultural information, we are interested in sophisticated classification schemes such as ontologies (ICOM/CIDOC Reference Model) and thesauri (the Getty’s Art & Architecture Thesaurus (AAT), the Thesaurus of Geographical Names (TGN), the United List of Artist Names (ULAN)). In addition, information about cultural artifacts is available in various data forms such as photos, plain ASCII files, HTML/SGML documents, relational and object databases and other unstructured or weakly structured exchange formats. To encompass syntactic heterogeneity of information we intend to use state of the art semistructured models combining object databases with weak typing features.
We address the issue of intelligent integration of application specific ontologies/thesauri and source specific metadata in order to define dynamic mediator schemata as well as enable flexible query formulation and processing. For such a purpose, we distinguish between the semantic and structural metadata of source descriptions to capture the two types of heterogeneity that were mentioned previously. In this context, registration, modification or withdrawal of a source should lead to minimal mediator reorganization. Moreover, users will have the possibility to interact at run-time with the system in order to guide mediator construction with specific data quality preferences (data accessibility, interpretability, usefulness, believability, etc.).
Specific Approach
We will use the ICOM/CIDOC ontology, that has been developed independently of the underlying information repositories, as the reference model for the organization of cultural information. Nevertheless, this ontology represents information entities and relationships in a quite abstract level (eg, Person, Artifact, Event, etc.) and in order to support more detailed semantic descriptions of sources we intend to incorporate related thesauri or authority data (AAT, TGN, ULAN etc).
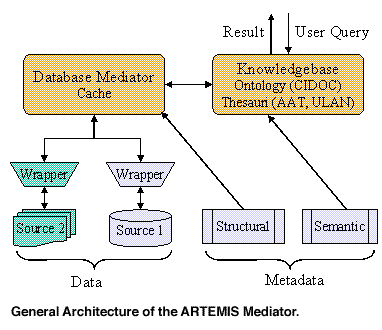
Furthermore, we will use object database support in order to build a semantic cache for object fusion, cache browsing and querying. The cache schema will be constructed dynamically from the user query and should reflect the structure of query results. Under this perspective we adopt a semistructured approach for its flexibility to capture schema changes and represent eventually incomplete information.
Query Processing
For query processing we have to address different issues which are well known for mediator based architectures. Among these issues the most important are (1) source selection with respect to a user query, (2) query rewriting with respect to the source semantics and structure. (3) query plan generation with respect to the wrapper query capabilities and (4) cache management. In order to select sources which might be relevant to some user query we will study new subsumption algorithms which take into consideration not only concept definition but also inter/intra thesaurus relationships between terms (eg broader/narrower, related, equivalent term etc.).
We are currently collaborating with different cultural organizations (National Museum of Denmark, Greek and French Ministries of Culture, Germanisches Nationalmuseum of Nürnberg and the Benaki Museum at Greece) for an application oriented evaluation of our approach.
Please contact:
Anne-Marie Vercoustre - INRIA
Tel: +33 1 3963 5662
E-mail: Anne-Marie.Vercoustre@inria.fr
Vassilis Christophides - FORTH
Tel: +30 81 39 16 28
E-mail: christop@ics.forth.gr