

ERCIM News No.35 - October 1998
ERCIM News No.35 - October 1998
Concept Index: Social Knowledge Construction from Documents
by Keiichi Nakata, Angi Voss, Marcus Juhnke and Thomas Kreifelts
With the rapid expansion of the Internet in the recent years, there is a potential for the Internet to become a place in which social activities take place. In the research framework ‘Social Web’ at GMD Institute for Applied Information Technology, scientists are exploring ways to facilitate social activities on the Internet such as meeting people with similar interests, forming groups and working together. In this research context, our group is interested in how social knowledge, ie, a body of knowledge that belongs to a group or community, can be captured and maintained.
The Concept Index is our first attempt initiated in April 1998. It is based on the assumption that in the Internet-based situation, members of a group would use documents as their main means of information exchange, and these documents in turn contain cues to what people know or are interested in, in words or phrases. These keyphrases (keywords and phrases) describe concepts which can be seen as the building blocks of knowledge. Once we can capture the concepts they can be shared, inspected, and enhanced by members of the group. The interactive and, more significantly, collaborative process of identifying related or associated concepts is expected to reveal the tacit knowledge held by the group as a whole. So far we have developed a first demonstrator which is used to conduct experiments on the validity of this approach.
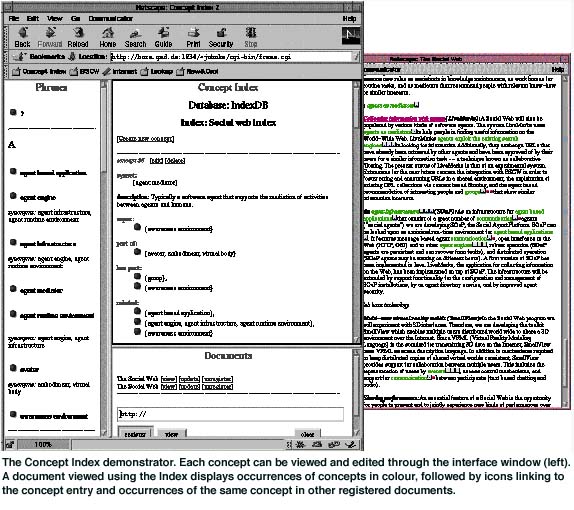
A Concept Index is typically constructed in the following manner. First, a document is registered with a collection of documents that share the Index. In this document, users can highlight keyphrases which are important or significant. These keyphrases are inserted into the Index. In the Index, users can inspect a concept description and may identify other words or phrases that would describe the same concept, or identify concepts that are strongly related to it. Types of such relations include super and sub concepts, and simple associations.
Synonyms and concept relations can also be imported from electronic thesauri, and through a text analysis technique known as text mining, to enhance the Index. Whenever a user views a document, all the occurrences of concepts in the Index are highlighted by colour. Since any member in the group can contribute to the Index, this means a user can see the keyphrases that others found important or interesting. Moreover, links to other documents in the collection that contain the same concept are automatically inserted, making it possible for the user to navigate from one document to the other through the concept space.
The task of identifying important and interesting concepts can be performed in a more direct fashion, for instance by asking the user using forms containing questions such as “List some keywords that best describe your interest“. However, collecting information of this nature in such a way is often cumbersome and cannot deal efficiently when user’s interests change and grows through the exposure to new information obtained through reading articles etc.
The approach taken by the Concept Index addresses this problem of knowledge acquisition and evolution. A user can simply mark the phrases they find interesting while writing, reading, or glancing through a document as you would do using a highlight marker on paper, and these keyphrases are automatically recorded in the Concept Index and updated as new documents arrive.
Once a Concept Index is generated, and enhanced by the members of the group who share the Index, it can evolve into a community language. Such a language consists of terms whose meanings are agreed upon by the group, and the concepts to which they refer. Since entries in the Index are always grounded in documents produced or accepted by the group, the concepts are implicitly defined by their usage.
Furthermore, a Concept Index may be used to memorise what people found interesting, leading to what may be called collective memory, ie, a collection of memories gathered and combined by a group of people. Using Concept Indexes generated by different groups to view the same document would result in different highlighting of the document, and we can observe various perspectives reflected by each Index.
Experiments are under way to evaluate the feasibility of this approach. One of the promising applications of Concept Indexes is query expansion and result filtering for Internet-based search. We plan to integrate Concept Indexes into our agent-based collaborative information seeking system in the future as a means for presentation and navigation.
Information on the Web at:
http://orgwis.gmd.de/projects/Coins/Please contact:
Keiichi Nakata - GMD
Tel: +49 2241 14 2317
E-mail: Keiichi.Nakata@gmd.de