

ERCIM News No.36 - January 1999
ERCIM News No.36 - January 1999
Bandera: Tools for Automated Reasoning about Software System Behaviour
by Matthew Dwyer, John Hatcliff, and David Schmidt
The Bandera Project aims to develop techniques and tools for automated reasoning about software system behavior, and to apply these tools to construct high-confidence mission-critical software. Automated reasoning is achieved by (1) mechanically creating high-level models of software systems using abstract interpretation and partial evaluation technologies, and then (2) employing model-checking techniques to automatically verify that software specifications are satisfied by the model. This project is a collaborative effort between the Laboratory for Specification, Analysis and Transformation of Software (SANTOS) at Kansas State University and researchers at the Universities of Hawaii and Massachusetts. Work in SANTOS is supported in part by grants from the US National Aeronautics and Space Administration (NASA), the Defense Advanced Research Projects Agency (DARPA) and the National Science Foundation (NSF).
Modern mission-critical software systems tend to be highly complex and concurrent, and they often have stringent correctness requirements. Pre-deployment reasoning about system behavior is crucial in application areas such as avionics, industrial, health care, military command-and-control where the cost of failure in the field is extremely high. Unfortunately, the inherent size and complexity of such systems prohibit classical validation techniques, such as testing, from providing high levels of assurance of reliability and correctness. Subtle timing-related defects in concurrent and embedded systems are very difficult to reveal through testing. To do so would generally require software testers to exercise all feasible execution paths and all possible interactions between software components. In modern systems, this is virtually impossible, and many deployed systems fail when real-world use leads to an execution path that was not foreseen by the software designers. Better verification techniques are sorely needed.
The Bandera tools allow software designers and quality assurance personnel to state properties about software source code that must hold along all execution paths. For example, in a priority-based concurrent system developers might want to assure that: (1) when two components of different priority levels attempt to access a shared resource the higher-priority components gets access first; (2) when a component attempts to access a resource it eventually succeeds. Ideally, the tools should automatically explore all execution paths and check to see if the given properties hold. With some properties this can be done, but in most cases the size of the system and the complexity of the specification makes this infeasible. In these cases, the user guides the tools in the construction of a smaller abstract model of the software system, and then the tools can automatically check to see if a given specification holds in the model. If the property holds in the model and if the model safely approximates the software system’s behavior, this guarantees that the property also holds in the original software system. If the property does not hold, the tools will generate a counter-example - a trace in the model system that violates the given property. By appropriately interpreting the counterexample, one can locate the source of the offending defect in the system being modeled.
In the process outlined above, safe and effective model creation is crucial for the approach to be successful. To make automatic checking tractable, the model must discard information about the program that is irrelevant to the property being verified. However, it must retain enough structure to reason about relevant execution paths. The Bandera tools use abstract interpretation, a rigorous semantics-based methodology for constructing static analyses of programs, to form safe abstractions of software, and partial evaluation and slicing techniques to build compact models. The figure gives the architecture of the tool suite for reasoning about Java programs.
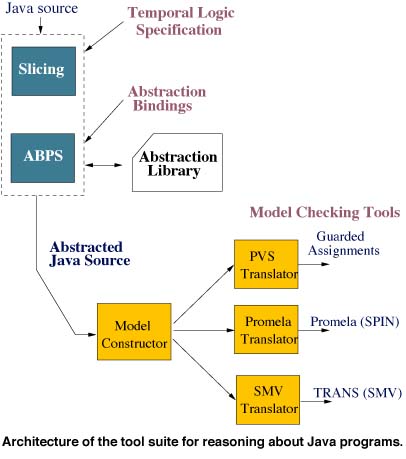
Given software component source code S and a property to be verified P, a slicing tool then cuts away portions of S that are irrelevant for verifying P. The user then selects abstract interpretation definitions to be used in abstracting the remaining program components. These definitions can be drawn from a library of common abstractions or they can be defined from scratch. Once the abstractions are specified, abstraction-based partial evaluation (ABPE) creates an abstracted and specialized version of the source program. The transition system generator compiles the abstract program to one of several existing model-checking tool input languages. If verification fails, counter-examples produced by the model-checking tools are rendered in terms of the original source program.
We have applied this methodology to several software systems written in Ada. We have validated correctness properties of a programming framework that supports parallelization of worklist algorithms; this framework has been used to implement a variety of scientific computing applications. We have also performed unit-level verification of generic stack, queue, and priority-queue implementations and demonstrated the ability of model checking to detect realistic implementation defects in such systems. The lessons learned from these experiences have provided important validation of and feedback to our ongoing design and implementation of Java model construction tools. We are working with the automated software engineering group at the NASA Ames Research Center to incorporate these tools into their avionics software workbench.
More information about this project is available at:
http://www.cis.ksu.edu/~santosPlease contact:
Matthew Dwyer, John Hatcliff, and David Schmidt - SANTOS Laboratory, Department of Computing and Information Sciences, Kansas State University
E-mail: {dwyer, hatcliff, schmidt}@cis.ksu.edu